机器学习中,核机是一类用于模式分析的算法,最知名的成员是支持向量机(SVM)。 这些方法用线性分类器解决非线性问题。[1]模式分析的一般任务是在数据集中发现并研究一般类型的关系(如聚类分析、排名、主成分分析、相关性分析、统计分类)。对许多解决此类任务的算法来说,原始表示的数据必须通过用户指定的特征映射明确转换为特征向量表示;相反,核方法只需要用户指定核,即用内积计算所有数据点对的相似性函数。核机中的特征映射是无限维的,但根据表示定理,只需输入有限维矩阵。在不并行处理的情况下,核机的计算速度会很慢。
核方法得名于核函数的使用,使其能在高维隐特征空间中运行,而无需计算空间中数据的坐标,只需计算特征空间中所有数据对的像之间的内积。这种运算比显式计算坐标更节约,称为“核技巧”。[2]核函数已被引入序列数据、图核函数、文本、图像及向量处理中。
能使用核的算法有核感知器、支持向量机(SVM)、高斯过程、主成分分析(PCA)、典型相关分析、岭回归、谱聚类、自适应滤波器等等很多算法。
大多数核算法都基于凸优化或特征问题,有很好的统计学基础。通常用统计学习理论(如拉德马赫复杂度)分析其统计特性。
动机与非正式解释
核方法可被视为基于实例的学习器:不是学习与输入特征相对应的固定参数集,而是“记忆”第 个训练样本
个训练样本 并学习相应权
并学习相应权 。预测不在训练集中的输入(未标记输入)是用未标记输入
。预测不在训练集中的输入(未标记输入)是用未标记输入 与每个训练输入
与每个训练输入 的相似性函数
的相似性函数 (称作核)。例如,核化二分分类器通常计算相似度的加权和
(称作核)。例如,核化二分分类器通常计算相似度的加权和
 ,
,
其中
 是核化二分分类器对无标输入的预测标签,其隐藏的真实标签
是核化二分分类器对无标输入的预测标签,其隐藏的真实标签 是我们感兴趣的;
是我们感兴趣的; 是核函数,度量了任意一对输入
是核函数,度量了任意一对输入  的相似性;
的相似性;- 和的范围是分类器训练集中的n个有标示例
 ;
;
 是由学习算法确定的训练样本的权重;
是由学习算法确定的训练样本的权重;- 符号函数
 决定预测分类结果
决定预测分类结果 属于正类还是负类。
属于正类还是负类。
核分类器的描述可追溯至1960年代核感知器的发明。[3]1990年代,随着支持向量机(SVM)的流行,人们发现其在手写识别等任务上的表现可与神经网络媲美。
数学:核技巧
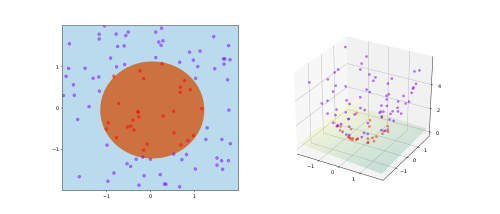 SVM,核为
SVM,核为 ,因此
,因此 。训练点被映射到三维空间,很容易找到分离超平面。
。训练点被映射到三维空间,很容易找到分离超平面。
核技巧避免了让线性学习算法学习非线性函数或决策边界所需的显式映射。 与
与 (输入空间),某些函数
(输入空间),某些函数 可表示为另一空间
可表示为另一空间 中的内积。函数 常被称为核或核函数。“核”在数学中用于表示加权和或积分的加权函数。
机器学习中某些问题比任意权函数更具结构性。若核能写成“特征映射”
中的内积。函数 常被称为核或核函数。“核”在数学中用于表示加权和或积分的加权函数。
机器学习中某些问题比任意权函数更具结构性。若核能写成“特征映射” ,满足
,满足

那么计算就能简化很多。关键的约束是 必须是适当的内积。另一方面,只要是内积空间,就不必明确表示出
必须是适当的内积。另一方面,只要是内积空间,就不必明确表示出 。另一种方法来自默瑟定理:只要空间
。另一种方法来自默瑟定理:只要空间 匹配了合适的测度确保函数满足默瑟条件,就存在隐定义的函数。
匹配了合适的测度确保函数满足默瑟条件,就存在隐定义的函数。
默瑟定理类似于线性代数中将内积与任意正定矩阵相关联的结果的推广。实际上,默瑟条件可以简化为这种更简单的情况:若 择计数测度
择计数测度 (计算集合
(计算集合 内部的点数),那么默瑟定理中的积分就简化为和式
内部的点数),那么默瑟定理中的积分就简化为和式

若对于中的所有有限点序列 及所有
及所有 个实值系数选择
个实值系数选择 (参考正定核),和式都成立,那么函数满足默瑟条件。
(参考正定核),和式都成立,那么函数满足默瑟条件。
一些依赖于原空间中任意关系的算法在别的环境中会有线性解释:的范围空间。线性解释让我们对算法有了更深入的了解。此外,在计算过程中通常无需直接计算,支持向量机就是这样。有人认为这种运行时间上的节省是其主要优点。研究人员也用它来证明现有算法的意义和特性。
理论上讲,关于 的格拉姆矩阵
的格拉姆矩阵 (有时也称为“核矩阵”[4]),其中
(有时也称为“核矩阵”[4]),其中 须是正半定(PSD)矩阵。根据经验,对于机器学习的启发式方法来说,若至少近似于相似性的直观概念,那么不满足默瑟条件的函数的选择可能仍有合理表现。[5]无论是不是默瑟核,仍可称为“核”。
须是正半定(PSD)矩阵。根据经验,对于机器学习的启发式方法来说,若至少近似于相似性的直观概念,那么不满足默瑟条件的函数的选择可能仍有合理表现。[5]无论是不是默瑟核,仍可称为“核”。
若核函数也是高斯过程中使用的协方差函数,那么格拉姆矩阵 也可称为协方差矩阵。[6]
也可称为协方差矩阵。[6]
应用
核方法的应用十分广泛,见于地理统计[7]、克里金法、反距离加权、三维重建、生物信息学、化学信息学、信息抽取和手写识别。
常用核函数
另见
参考文献
- ^ Kernel method. Engati. [2023-04-04]. (原始内容存档于2023-04-04) (英语).
- ^ Theodoridis, Sergios. Pattern Recognition. Elsevier B.V. 2008: 203. ISBN 9780080949123.
- ^ Aizerman, M. A.; Braverman, Emmanuel M.; Rozonoer, L. I. Theoretical foundations of the potential function method in pattern recognition learning. Automation and Remote Control. 1964, 25: 821–837. Cited in Guyon, Isabelle; Boser, B.; Vapnik, Vladimir. Automatic capacity tuning of very large VC-dimension classifiers. Advances in neural information processing systems. 1993. CiteSeerX 10.1.1.17.7215
 .
.
- ^ Hofmann, Thomas; Scholkopf, Bernhard; Smola, Alexander J. Kernel Methods in Machine Learning. The Annals of Statistics. 2008, 36 (3). S2CID 88516979. doi:10.1214/009053607000000677 .
- ^ Sewell, Martin. Support Vector Machines: Mercer's Condition. Support Vector Machines. [2014-05-30]. (原始内容存档于2018-10-15).
- ^ Rasmussen, C. E.; Williams, C. K. I. Gaussian Processes for Machine Learning. 2006.
- ^ Honarkhah, M.; Caers, J. Stochastic Simulation of Patterns Using Distance-Based Pattern Modeling. Mathematical Geosciences. 2010, 42 (5): 487–517. S2CID 73657847. doi:10.1007/s11004-010-9276-7.
阅读更多
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis. Cambridge University Press. 2004.
- Liu, W.; Principe, J.; Haykin, S. Kernel Adaptive Filtering: A Comprehensive Introduction. Wiley. 2010. ISBN 9781118211212.
- Schölkopf, B.; Smola, A. J.; Bach, F. Learning with Kernels : Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press. 2018. ISBN 978-0-262-53657-8.
外部链接
